コンピュータが勝手にお勉強!「ディープラーニング」ってなんだ?

先月末、Google開発の人工知能=AI「アルファ碁」が、中国で「世界最強」と言われていた囲碁棋士と対決し、3戦全勝したことがニュースになりました。
チェスは1988年、将棋は2013年に初めてAIに敗北したものの、囲碁は盤面が広く打ち手が複雑なことから、「人類最後の砦」としてAIが勝つにはあと10年かかると言われていましたが、驚異的な進化を遂げてトップ棋士に完勝しました。
その進化の原動力となったのが「ディープラーニング」です。
チェスは1988年、将棋は2013年に初めてAIに敗北したものの、囲碁は盤面が広く打ち手が複雑なことから、「人類最後の砦」としてAIが勝つにはあと10年かかると言われていましたが、驚異的な進化を遂げてトップ棋士に完勝しました。
その進化の原動力となったのが「ディープラーニング」です。
開発者がすべてを決めるプログラムから「機械学習」へ
従来のコンピュータは、あらかじめ組まれているプログラムに従って処理していきます。つまり、プログラムという指示があって初めてコンピュータは動作することができます。
ここで、コンピュータに「モビルスーツの分類」をしてもらいましょう。
ここで、コンピュータに「モビルスーツの分類」をしてもらいましょう。
まずは、画像に紐づいている情報を元に画像を分類していきます。
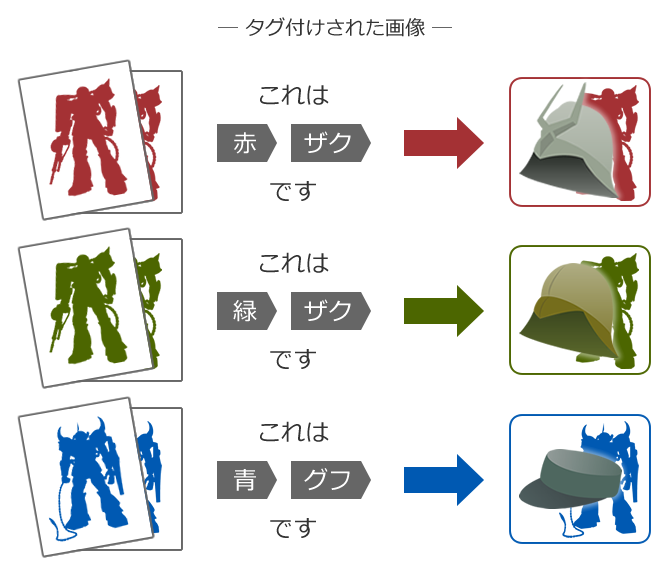
うーん、あらかじめ人が全ての画像にタグを付けておかないと分類できません。
これだとタグ付けされていない画像が出てきたときに困りますね。
そうこうしているうちに2011年、「ビッグデータ」が登場し、あっという間にビッグデータの活用がIT業界の重要ワードになるとともに、「機械学習」という技術が生まれました。
機械学習ではすべての動作をプログラムするのではなく、AIがデータをもとに学習して、法則を見つけ出して結果を出します。
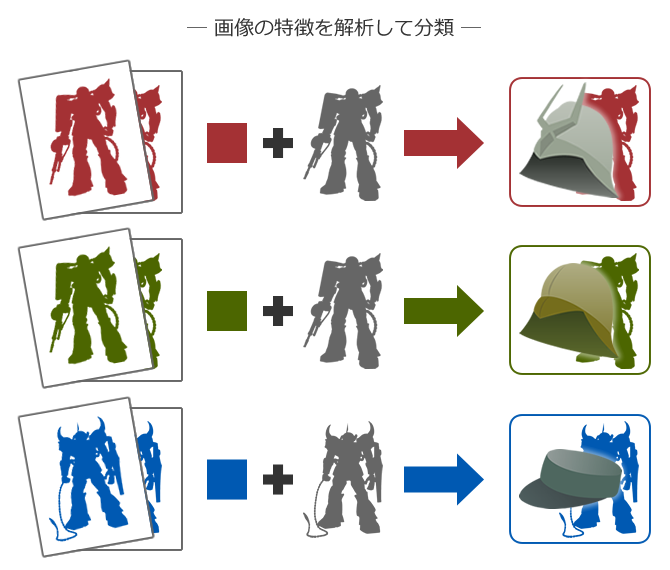
これは緑のザク」「これは赤いザク」「これは青いグフ」・・といったデータを大量に読み込んで解析することで、「これは色が赤で形がザクだからシャア専用!」を判断することができます。
「ビッグデータ」を活用してコンピュータが自分から学習
人間の脳の神経回路を元にした数学モデル「ニューラルネットワーク」を元に、機械学習を進化させたのが「ディープラーニング」です。「機械学習」では
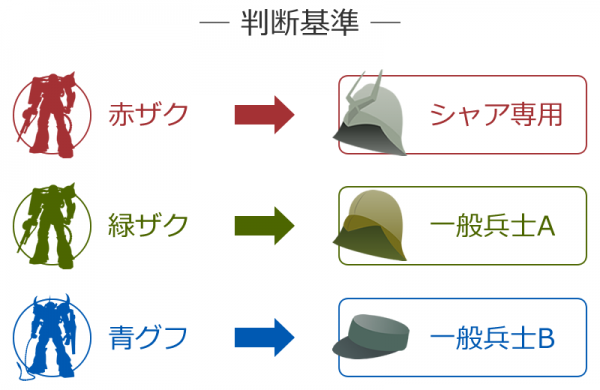
赤ザク=シャア専用
緑ザク=一般兵士A
青グフ=一般兵士B
という判断基準を指定する必要がありましたが、ディープラーニングでは何を基準に分類したらいいか、もAIが自分で学習して判断するようになります。
赤ザク=シャア専用
緑ザク=一般兵士A
青グフ=一般兵士B
という判断基準を指定する必要がありましたが、ディープラーニングでは何を基準に分類したらいいか、もAIが自分で学習して判断するようになります。
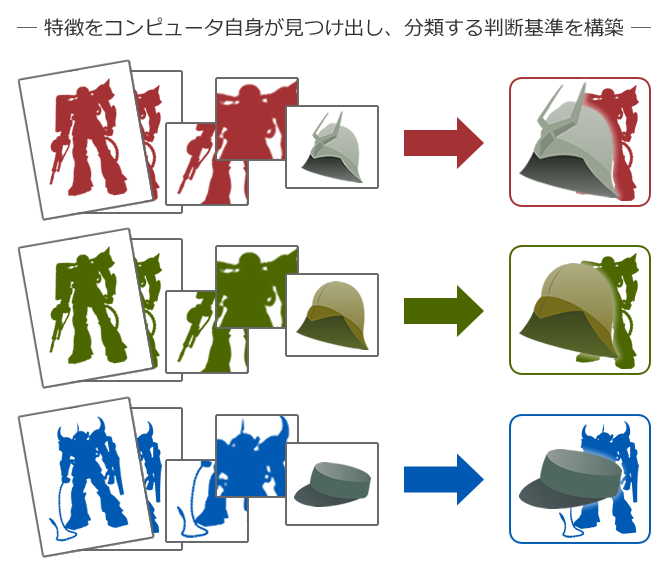
「赤いザクに乗っているシャア」「緑のザクに乗っている一般兵士」「青いグフに乗っている一般兵士」・・といったデータから、
「このシルエットのモビルスーツは緑と赤がある」
「シャアはこの武器の赤いモビルスーツに乗っている」
「一般兵士は緑には乗るが赤には乗らない」
「一般兵士は青に乗るがシャアは乗らない」
等々解析し、モビルスーツの画像を分類する判断基準を自分で見つけ出します。
そこで「このグループは『赤いシャアのザク』です」というラベルを与えてあげると、大破したモビルスーツでも最低限の特徴が残っていれば「これはシャア専用!」と判断することができます。
「このシルエットのモビルスーツは緑と赤がある」
「シャアはこの武器の赤いモビルスーツに乗っている」
「一般兵士は緑には乗るが赤には乗らない」
「一般兵士は青に乗るがシャアは乗らない」
等々解析し、モビルスーツの画像を分類する判断基準を自分で見つけ出します。
そこで「このグループは『赤いシャアのザク』です」というラベルを与えてあげると、大破したモビルスーツでも最低限の特徴が残っていれば「これはシャア専用!」と判断することができます。
こうしてAIはどんどん学習して進化してさらに学習して・・ついに3大ボードゲームのチェス・将棋・囲碁を制覇してしまいました。
便利?脅威?未来はどうなるんだろう?
AIが発達したコンピュータ社会をテーマにした映画や小説など、サイエンス・フィクション(SF)ではロボットや人工生命体は人類の敵だったり夢の生活だったりいろんな姿で描かれていますが、やっぱり未来はターミネーターよりアトムの方ががいいなぁ。。。


